Java 题库
1. Java基础内容
2. 异常
3. 集合
3.1 List和Set的区别
- List,Set都是继承自Collection接口
- List特点:元素有放入顺序,元素可重复
- Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(元素虽然无放入顺序,但是元素在set中的位置是由该元素的HashCode决定的,其位置其实是固定的,加入Set的Object必须定义equals()方法,另外list支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能有迭代,因为他无序,无法用下标来取得想要的值)
- Set和List对比
-
向HashSet中add()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合equals方法比较。
-
HashSet中的add()方法会使用HashMap的add()方法。以下是HashSet部分源码

-
HashMap的key是唯一的,由上面的代码可以看出HashSet添加进去的值就是作为HashMap的key。所以不会重复(HashMap比较key是否相等是先比较hashCode再比较equals)
3.3 HashMap是线程安全的么,为什么不是线程安全的(最好画图说明多线程环境下不安全)?
-
不是线程安全的
-
如果有两个线程A和B,都进行插入数据,刚好这两条不同的数据经过哈希计算后得到的哈希码是一样的,且该位 置还没有其他的数据。所以这两个线程都会进入我在上面标记为1的代码中。假设一种情况,线程A通过if判断,该 位置没有哈希冲突,进入了if语句,还没有进行数据插入,这时候 CPU 就把资源让给了线程B,线程A停在了if语句 里面,线程B判断该位置没有哈希冲突(线程A的数据还没插入),也进入了if语句,线程B执行完后,轮到线程A执 行,现在线程A直接在该位置插入而不用再判断。这时候,你会发现线程A把线程B插入的数据给覆盖了。发生了线 程不安全情况。本来在 HashMap 中,发生哈希冲突是可以用链表法或者红黑树来解决的,但是在多线程中,可能 就直接给覆盖了。
-
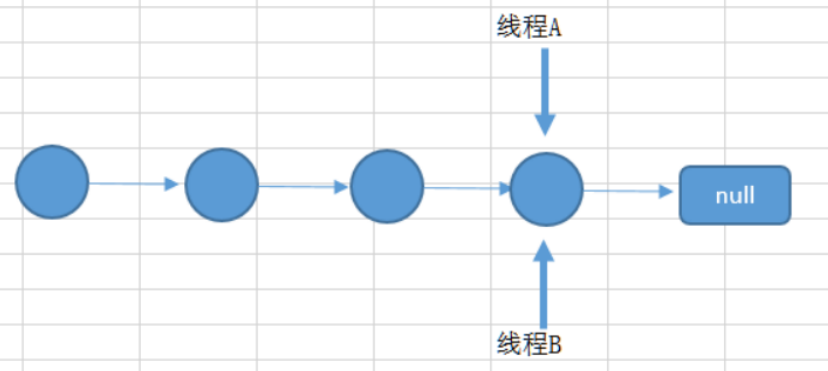
上面所说的是一个图来解释可能更加直观。如下面所示,两个线程在同一个位置添加数据,后面添加的数据就覆盖 住了前面添加的。
-

-
如果上述插入是插入到链表上,如两个线程都在遍历到最后一个节点,都要在最后添加一个数据,那么后面添加数据的线程就会把前面添加的数据给覆盖住,则
-
-
在扩容的时候也可能会导致数据不一致,因为扩容是从一个数组拷贝到另外一个数组
3.4 HashMap的扩容过程
-
当向容量添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值,即当前数组的长度乘以加载因子的值的时候,就要自动扩容了
-
扩容(resize)就是重新计算容量,向hashmap对象里不停的添加元素,而Hashmap对象内部的数组无法装在更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组 ,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
-
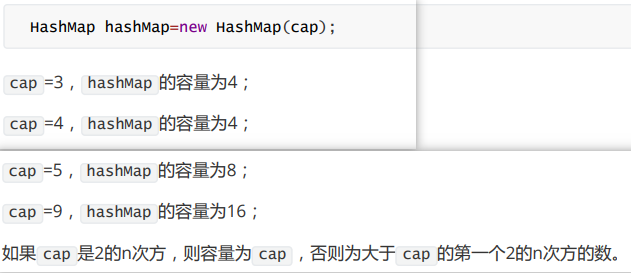
3.5 HashMap1.7与1.8的区别,说明1.8做了哪些优化,如何优化的?
-
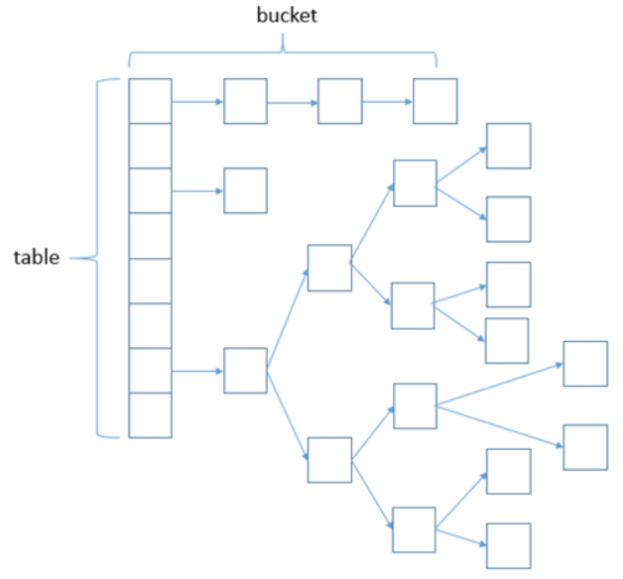
HashMap结构图
-
-
在JDK1.7及之前的版本中,HashMap又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储
-
JDK1.8中,当同一个hash值(Table上元素)的链表节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树,这就是JDK7与JDK8中HashMap实现的最大区别
其下基于JDK1.7.0_80与JDK1.8.0_66做的分析
JDK1.7中
- 使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同,或者hashcode取模后的结果相同,那么这些key会被定位到Entry数组的同一个格子里,这些key会形成一个链表
- 在hashcode特别差的情况下,比如说所有key的hashcode都相同,这个链表可能会很长,那么put/get操作都可能需要遍历这个链表,也就是说时间复杂度在最差情况下会退化到O(n)
JDK1.8中
- 使用一个Node数组来存储数据,但这个Node可能是链表结构,也可能是红黑树结构
- 如果插入的key的hashcode相同,那么这些key也会被定位到Node数组的同一个格子里
- 如果同一个格子里的key不超过8个,使用链表结构存储
- 如果超过了8个,那么会调用treeifyBin函数,将链表转换为红黑树