最佳答案
基指针和堆栈指针到底是什么?他们指的是什么?
使用来自维基百科的这个例子,其中DrawSquare()调用DrawLine(),
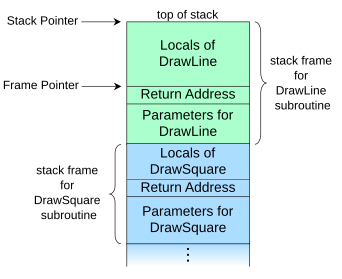
(请注意,这张图底部是高地址,顶部是低地址。)
有人能解释一下在这个上下文中ebp和esp是什么吗?
从我所看到的,我想说堆栈指针总是指向堆栈的顶部,而基指针指向当前函数的开始?还是别的什么?
edit:我指的是在windows程序的上下文中
edit2: eip也是如何工作的呢?
edit3:我有下面的代码从msvc++:
var_C= dword ptr -0Ch
var_8= dword ptr -8
var_4= dword ptr -4
hInstance= dword ptr 8
hPrevInstance= dword ptr 0Ch
lpCmdLine= dword ptr 10h
nShowCmd= dword ptr 14h
它们似乎都是dwords,因此每个都占用4个字节。所以我可以看到从hInstance到var_4有一个4字节的空白。它们是什么?我猜这是回复地址,可以从维基百科的图片中看到?
(编者注:从迈克尔的回答中删除了一段很长的引语,这段引语不属于这个问题,但后面的问题被编辑进去了):
这是因为函数调用的流程是:
* Push parameters (hInstance, etc.)
* Call function, which pushes return address
* Push ebp
* Allocate space for locals
我的问题(我希望是最后一个!)现在是,从我弹出我想要调用的函数的参数到序言结束的那一刻到底发生了什么?我想知道ebp, esp在这些时刻是如何演变的(我已经理解了prolog是如何工作的,我只想知道在我把参数推到堆栈上和在prolog之前发生了什么)。